Naresh Shanbhag – Research
Overview
 |
We are interested in designing energy-efficient inference systems based on machine learning, communications and signal processing for computer vision, speech recognition, biomedicine, target recognition, and other applications. Our research focuses on unraveling fundamental trade-offs between energy, latency, and accuracy of decision-making systems implemented on resource-constrained platforms utilizing nanoscale integrated circuits and devices. We demonstrate these trade-offs via system analysis, architecture design, and integrated circuit prototypes. This systems-to-devices journey harnesses concepts from a diversity of fields including information theory, statistical signal processing, detection and estimation, VLSI architectures, and digital and analog integrated circuits. See our Proceedings of IEEE paper. |
Research Focus Areas
Resource-efficient Machine Learning for the Edge
Projects in this area focus on the problem of designing machine learning algorithms under stringent constraints on computational, storage, and communication resources typical of Edge platforms such as autonomous agents, wearables, and IoT. The goal is to maximize the information extraction and decision-making capabilities of embedded platforms such as human-centric (wearables), autonomous (drones), and IoT. Specific topics include - analytically obtaining minimum precision requirements of deep neural networks (ICML’17 paper on minimum precision requirements for inference, ICLR’19 paper on minimum precision requirements for training, ICLR’19 paper on ultra low-precision training, EECV’20 paper on differentiable branch quantization), principled design of efficient adversarially robust neural networks (NeurIPS’21 Spotlight paper generalized depth wise separable convolutions, ICML’22 paper on adversarial vulnerability of randomized ensembles), learning algorithms for emerging deep in-memory architectures, and prototyping of these algorithms on resource-constrained platforms. These projects require a strong analytical background complemented by a drive to see the impact of theory in practice, i.e., hardware realizations.
Energy-efficient In-memory Computing (IMC) Architectures for Deep Learning
In this focus area, we explore the design of energy-efficient in-memory accelerators for deep learning. Proposed by our group in 2014 (see our ICASSP’14 paper), IMCs address the high energy and latency costs of data movement between processor and memory by embedding analog computations deeply into the memory core. Multiple silicon prototypes from our group and others have demonstrated up to 100X reduction in the decision-level energy-latency product for machine learning algorithms over a fixed-function von Neumann equivalent. Today, IMC design is an active area of research world-wide. These projects require a solid background in integrated circuit design complemented with an ability to conduct systems analysis. See our IEEE Proceedings paper, the 2018 IEEE Spectrum article highlighting our work, and our book on the topic.
Our group has benchmarked an extensive collection of IMC and digital accelerator IC designs. See our CICC’21 invited paper showing recent trends in IMC design. A downloadable IMC benchmarking repository of metrics extracted from published IC prototypes in ISSCC, VLSI, CICC, (and ESSCIRC), since 2018, is also available. The repository comprises a database and a Python code to enable users to generate their own plots.
Energy-efficient High Data Rate Communications
This has been a long-standing research focus area for our group since 1995. The objective being to cross-optimize across communication algorithms (modulation, coding, equalization), VLSI architectures, and integrated circuit implementations, to realize energy efficient data transmission systems. These include fast FEC decoders (IEEE Transactions on VLSI’03 paper on high-speed LDPC decoders, the IEEE Transactions on VLSI’01 paper on high-speed Reed-Solomon decoders, and the IEEE Transactions on Information Theory’11 paper on VLSI architectures for soft-decision decoding of Reed-Solomon codes), codes for on-chip busses (IEEE Transactions on CAD’07 paper on joint equalization and coding), serial links (CICC’12 paper on an ECC-based serial link and the IEEE Journal of Solid-State Circuits’05 paper on 8Gb/s source-synchronous link), digital subscriber line (DSL) receivers (IEEE Transactions on Signal Processing paper on ATM-LAN and VDSL system design), and optical links (IEEE Journal of Solid-State Circuits’06 paper on OC-192 electronic dispersion compensation chip-set that received the 2006 IEEE Solid-State Circuits Society best paper award and catalyzed the area of ADC-based high-speed links).
Our current research activities in this area addresses the connectivity challenges inherent in heterogeneous integration of chiplets as well as short range high data-rate electrical and optical links within a data center.
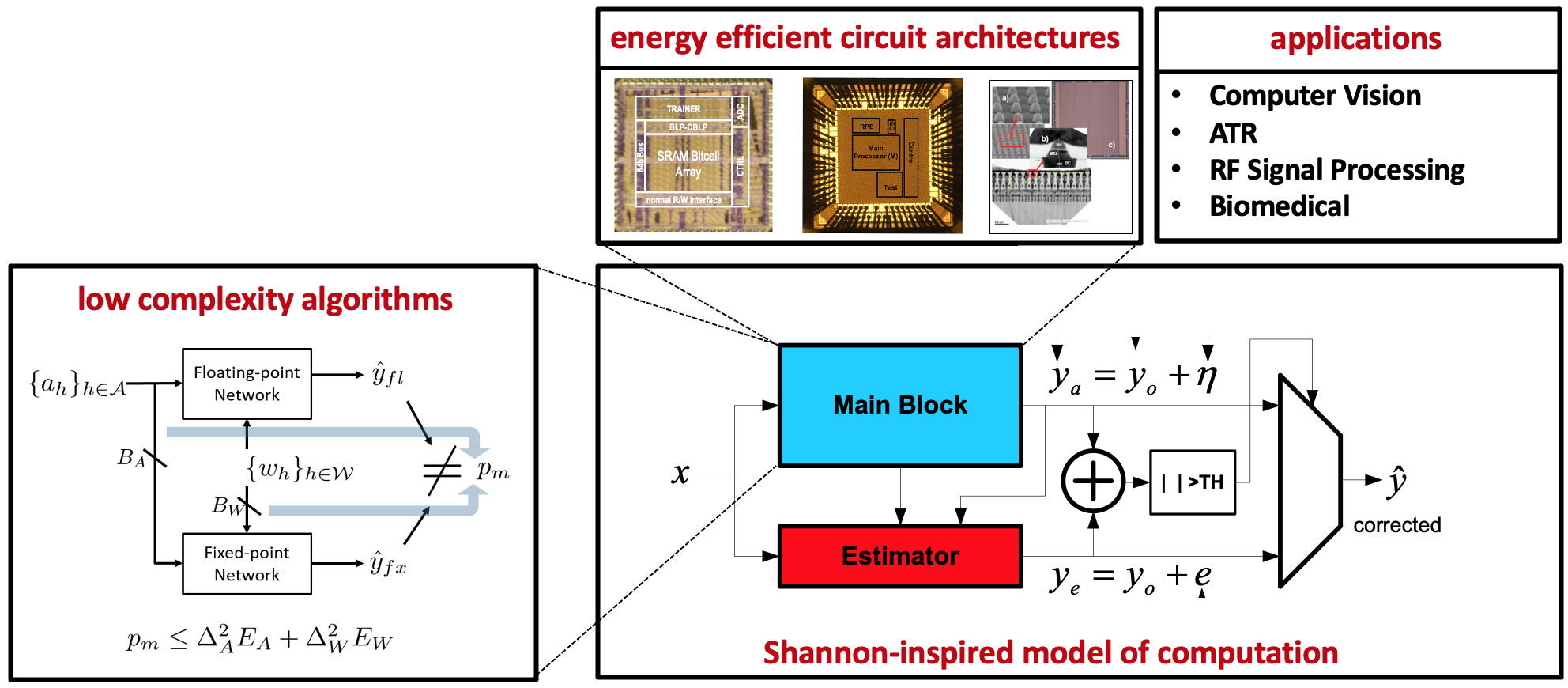
Shannon-inspired Statistical Error Compensation (SEC)
This focus area explores the development and application of methods for compensating for computational and memory errors which arise when integrated circuits are operated close to the limits of their energy efficiency and latency, e.g., DIMA. Proposed by our group in 1997, the Shannon-inspired model of computation calls for determining limits on energy efficiency of computation using information-theoretic concepts and developing efficient statistical error compensation (SEC) methods of computational errors based on statistical estimation and detection theory. Our recent work has focused on applying the vast portfolio of SEC methods developed over the years to the design of energy-efficient inference systems in silicon. This line of work requires a strong background in estimation and detection theory complemented with experience in VLSI architectures and circuits. See our IEEE Journal of Solid-State Circuits’13 paper on a subthreshold ECG classifier IC, the IEEE Spectrum’10 article highlighting our work, and our Proceedings of IEEE paper providing an overview of SEC methods to realize efficient machine learning systems in silicon.
Sponsors
We gratefully acknowledge the financial support of our research by the National Science Foundation, the Defense Advanced Projects Agency (DARPA), Air Force Research Laboratory (AFRL),
the Semiconductor Research Corporation (SRC), the Center for Brain-inspired Computing (C-BRIC), Texas Instruments, Sandia National Laboratories, the Systems on
Nanoscale Information fabriCs (SONIC) Center, the Gigascale Systems Research Center (GSRC), Micron, IBM, GlobalFoundries, Intel Corporation, National Semiconductor, Rockwell, Analog Devices, and FutureWei Technologies.